背景
最近工作中大量使用到Elasticsearch,需要通过Bulk操作将大量数据推到Elasticsearch中,但是发现有个别推数据的分布式任务一直不能结束,通过Thread Dump发现SchedulerX-ConsumerThread处于休眠状态,Thread Dump信息见下图:
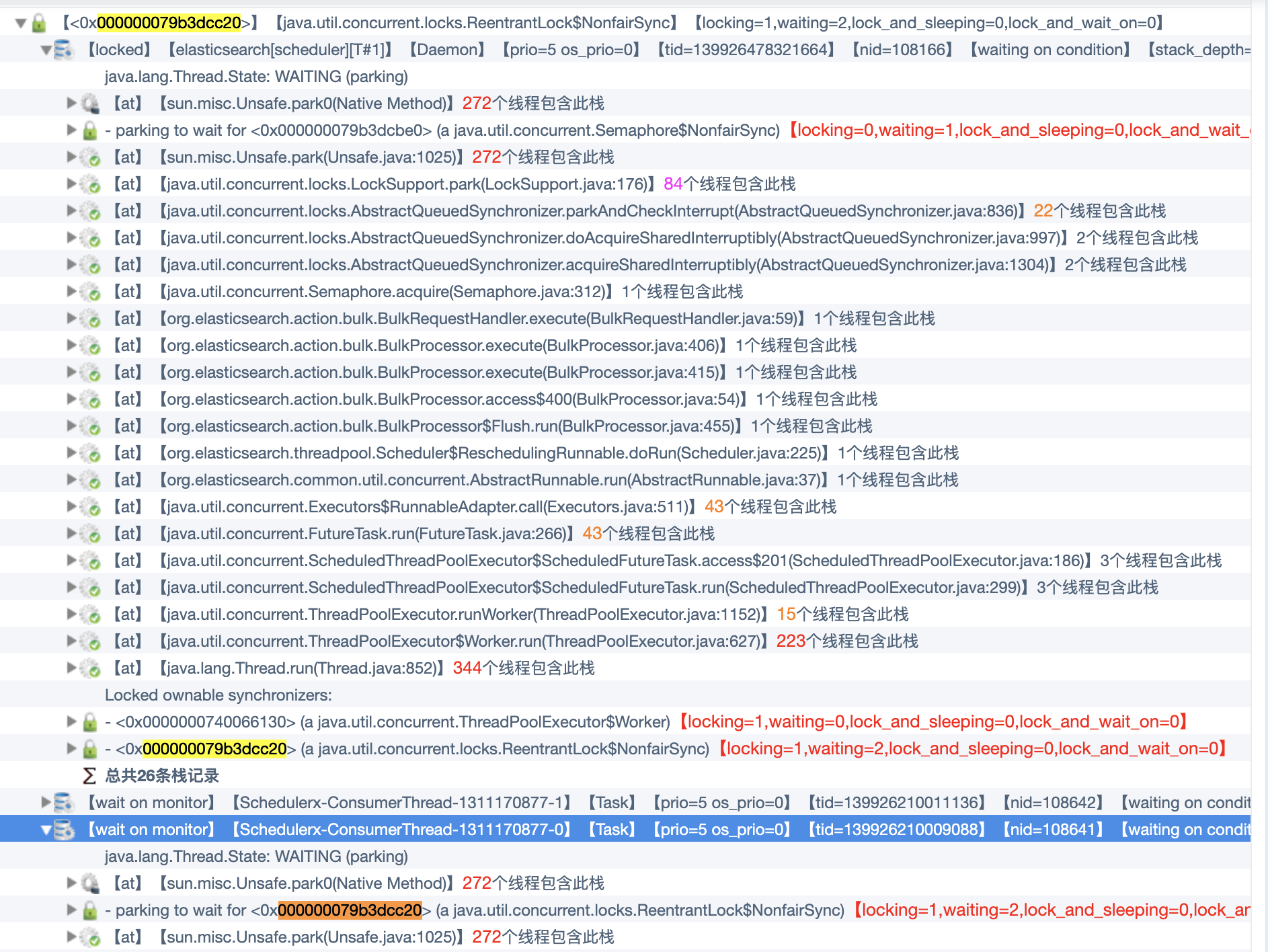
思路
通过上图的调用栈信息可知,SchedulerX-ConsumerThread在等待锁,而该锁又被 elasticsearch[scheduler][T#1] 所占有,通过locked ownable synchronizers可知它不但持有ReentrantLock而且还锁定了ThreadPoolExecutor, elasticsearch[scheduler][T#1] 不释放锁的原因是由于在等待一个信号量。分析到这里,就可以知道从哪儿入手了,接下来就可以进入到代码里面去看看到底发生了什么事情。
elasticsearch-rest-high-level-client 7.4.2版本中的BulkRequestHandler.java代码54行->92行如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39public void execute(BulkRequest bulkRequest, long executionId) {
Runnable toRelease = () -> {};
boolean bulkRequestSetupSuccessful = false;
try {
listener.beforeBulk(executionId, bulkRequest);
semaphore.acquire();
toRelease = semaphore::release;
CountDownLatch latch = new CountDownLatch(1);
retry.withBackoff(consumer, bulkRequest, ActionListener.runAfter(new ActionListener<BulkResponse>() {
@Override
public void onResponse(BulkResponse response) {
listener.afterBulk(executionId, bulkRequest, response);
}
@Override
public void onFailure(Exception e) {
listener.afterBulk(executionId, bulkRequest, e);
}
}, () -> {
semaphore.release();
latch.countDown();
}));
bulkRequestSetupSuccessful = true;
if (concurrentRequests == 0) {
latch.await();
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
logger.info(() -> new ParameterizedMessage("Bulk request {} has been cancelled.", executionId), e);
listener.afterBulk(executionId, bulkRequest, e);
} catch (Exception e) {
logger.warn(() -> new ParameterizedMessage("Failed to execute bulk request {}.", executionId), e);
listener.afterBulk(executionId, bulkRequest, e);
} finally {
if (bulkRequestSetupSuccessful == false) { // if we fail on client.bulk() release the semaphore
toRelease.run();
}
}
}
通过代码可知,semaphore的释放是由ActionListener.runAfter来完成。也就是说是bulk flush成功那么就顺利释放,如果失败就进入retry逻辑,semaphore暂时不释放,得等到retry之后再判断是否释放。由于flush和retry公用一个scheduler,每个scheduler会有一个线程池,加上前面 elasticsearch[scheduler][T#1] 锁定了一个ThreadPoolExecutor,所以问题的核心点随之浮出水面。
elasticsearch-rest-high-level-client 7.4.2版本中的Scheduler.java代码56行->63行如下:1
2
3
4
5
6
7
8static ScheduledThreadPoolExecutor initScheduler(Settings settings) {
final ScheduledThreadPoolExecutor scheduler = new SafeScheduledThreadPoolExecutor(1,
EsExecutors.daemonThreadFactory(settings, "scheduler"), new EsAbortPolicy());
scheduler.setExecuteExistingDelayedTasksAfterShutdownPolicy(false);
scheduler.setContinueExistingPeriodicTasksAfterShutdownPolicy(false);
scheduler.setRemoveOnCancelPolicy(true);
return scheduler;
}
结论
通过上面的代码可知,线程池只有一个线程,flush任务占用了一个线程就是上面的 elasticsearch[scheduler][T#1] ,导致retry任务没有线程资源可用,但是retry的任务却又占有信号量,所以这样便完成了一个环状等待。这是一种高级的死锁,不能简单的通过锁的依赖来排查到循环等待的情况。
当我们分析出问题的关键点,那么就简单了。通过Github和Stack Overflow一搜会发现bulk操作长久以来都存在这种问题,最新的pull request能够解决该问题,只需要升级client到7.5.0及以上即可。